from torch.optim.lr_scheduler import LambdaLR, MultiplicativeLR, StepLR, MultiStepLR
from torch.optim.lr_scheduler import ConstantLR, LinearLR, ExponentialLR, CosineAnnealingLR
from torch.optim.lr_scheduler import ReduceLROnPlateau, CosineAnnealingWarmRestarts
import matplotlib.pyplot as plt
%matplotlib inline
- LambdaLR
- MultiplicativeLR
- StepLR
- MultiStepLR
- ConstantLR
- LinearLR
- ExponentialLR
- CosineAnnealingLR
- ReduceLROnPlateau
- CosineAnnealingWarmRestarts
import torch.optim as optim
from torch import nn
class Config:
epoch=30
cfg = Config()
LambdaLR
根据传入的匿名函数lambda进行学习率的调整。调整的学习率 = 最初学习率 * 匿名函数返回值
- lr_lambda: 可以指定一组匿名函数lambda,每个lambda应用到对应的optimizer上去。该函数的输入是当前的epoch数值。
def train(model, optimizer, scheduler, cfg):
lrs = []
lrs.append(optimizer.state_dict()['param_groups'][0]["lr"])
for i in range(cfg.epoch):
# train
# valiadation
optimizer.step()
scheduler.step()
lrs.append(optimizer.state_dict()['param_groups'][0]["lr"])
return lrs
model = nn.Linear(10, 1)
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = LambdaLR(optimizer, lr_lambda=[lambda epoch: epoch / cfg.epoch])
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)

MultiplicativeLR
根据匿名函数的返回值进行调整学习率,调整的学习率 = 当前学习率 * 匿名函数的返回值。这和之前不同的是,这里做的是累积的乘法。
- lr_lambda: 可以指定一组匿名函数lambda,每个lambda应用到对应的optimizer上去。该函数的输入是当前的epoch数值。
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = MultiplicativeLR(optimizer, lr_lambda=[lambda epoch: 0.9])
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)
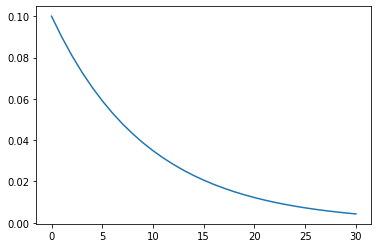
StepLR
每经过step_size个epoch后就进行衰减,衰减的因子为gamma。调整的学习率 = 当前的学习率 * gamma
-
step_size: 每经过step_size个epoch进行衰减
-
gamma: 衰减的因子
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = StepLR(optimizer, step_size=10, gamma=0.8)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)
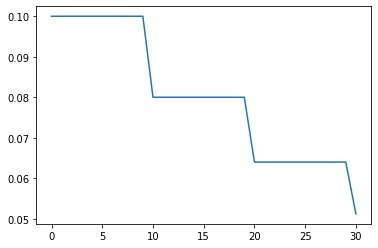
MultiStepLR
在特定的epoch处进行学习率衰减,衰减的因子为gamma,调整的学习率 = 当前学习率 * gamma
-
milestones: 包含一系列进行衰减的epoch
-
gamma: 衰减因子
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = MultiStepLR(optimizer, milestones=[3, 6, 9, 15, 20], gamma=0.5)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)
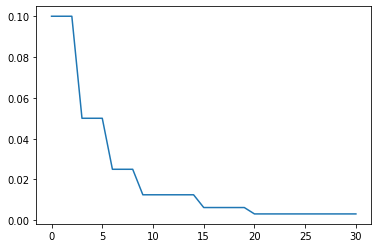
ConstantLR
学习率按某个常量持续指定的epoch后,再恢复初值。该常量为最初学习率乘衰减因子
-
factor: 衰减因子
-
total_iters: 持续多少个epoch
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = ConstantLR(optimizer, factor=0.3, total_iters=10)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)

LinearLR
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = LinearLR(optimizer, start_factor=0.3, end_factor=1.0, total_iters=10)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)
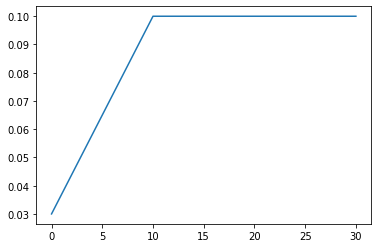
ExponentialLR
每隔一步就进行衰减,衰减的因子为gamma,调整的学习率 = 当前学习率 * gamma
- gamma: 衰减因子
optimizer = optim.Adam(model.parameters(), 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)
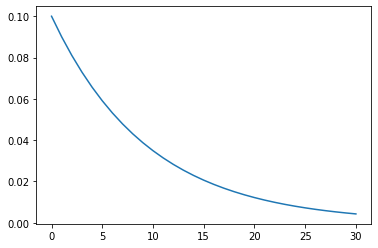
CosineAnnealingLR
余弦退火衰减法。
-
T_max: lr变动的最小正周期是2T_max。如果要保证在最后的几个epoch学习率是不断减小的。那么T_max应该满足这样的关系:epoch = (2k+1)T_max
-
eta_min: 最小的学习率
optimizer = optim.Adam(model.parameters(), 1e-4)
scheduler = CosineAnnealingLR(optimizer, T_max=6, eta_min=1e-5)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)
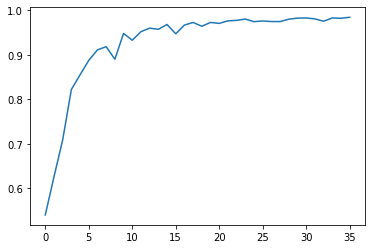
ReduceLROnPlateau
这种Scheduler可以跟踪指标,当某个指标不再满足提升的时候就进行学习率衰减。
- mode: min或者max。对于acc之类的指标用max,对于loss之类的指标用min
- factor: 衰减的因子
- patience: 若patience个epoch内跟踪的指标不提升,就衰减
- threshold: 对跟踪的指标设定的提升阈值
- min_lr: 最小的学习率
auc = [
0.54, 0.6256, 0.7087, 0.8219, 0.8549,
0.8873, 0.9109, 0.918, 0.8899, 0.9478,
0.9325, 0.9518, 0.9597, 0.9571, 0.9679,
0.9471, 0.9666, 0.9725, 0.964, 0.9725,
0.9704, 0.9761, 0.9772, 0.9801, 0.9743,
0.9758, 0.9746, 0.9745, 0.9798, 0.9823,
0.9826, 0.9805,0.9752, 0.9826, 0.9818,
0.9842
]
model = nn.Linear(10, 1)
optimizer = optim.Adam(model.parameters(), 1e-3)
scheduler = ReduceLROnPlateau(optimizer, mode="max", factor=0.5, patience=3, threshold=0.001, min_lr=1e-5)
lrs = []
lrs.append(optimizer.state_dict()['param_groups'][0]["lr"])
for i in range(len(auc)):
# train
# valiadation
optimizer.step()
scheduler.step(auc[i])
lrs.append(optimizer.state_dict()['param_groups'][0]["lr"])
plt.plot(auc)
plt.plot(lrs)

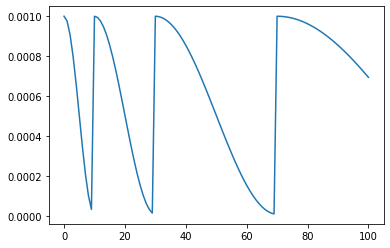
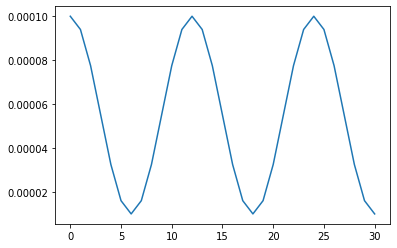
CosineAnnealingWarmRestarts
带热重启的余弦退火。在开始阶段,学习率就进行退火,然后到达T_0的时候,进行第0次热重启。以后每隔 \(T_{t+1}= T_t*T_{mult}\) 后进行一次热重启。\(T_t\)表示第t次间隔\(T_t\)个epoch再进行热重启。在下面的例子中。T的序列为[10, 20, 40, 80],从而热重启的epoch的序列为[10, 10+20, 30+40, 70+80]
- T_0: 第一次热重启的epoch
- T_mult: T增长的倍数
- eta_min: 最小的学习率,默认是0
cfg.epoch = 100
optimizer = optim.Adam(model.parameters(), 1e-3)
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=2, eta_min=1e-5)
lrs = train(model, optimizer, scheduler, cfg)
plt.plot(lrs)